内核开发笔记
内核空间和用户空间的概念以及内核空间和用户空间的数据拷贝
可以调用copy_from_user和copy_to_user来进行用户和内核空间的读写
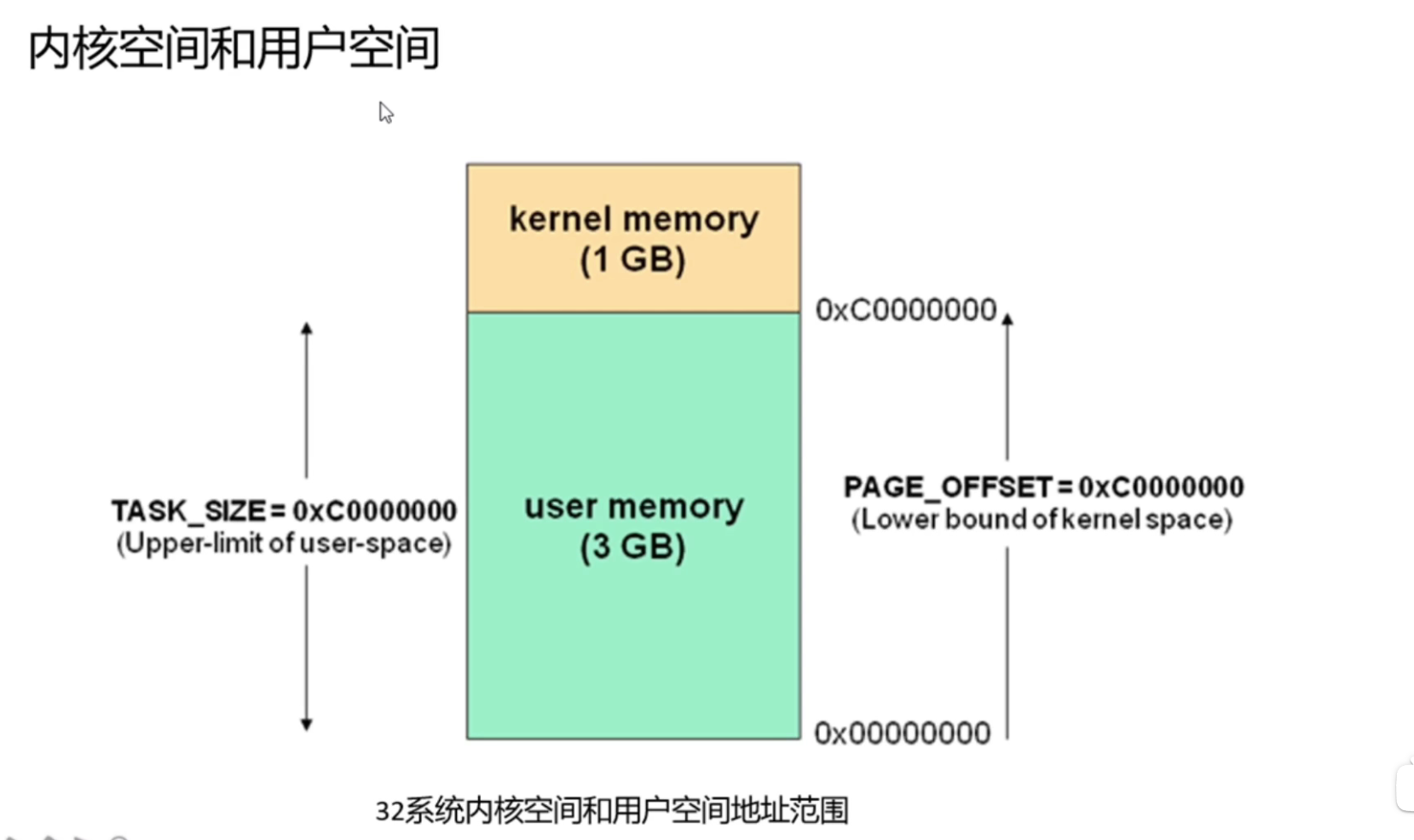
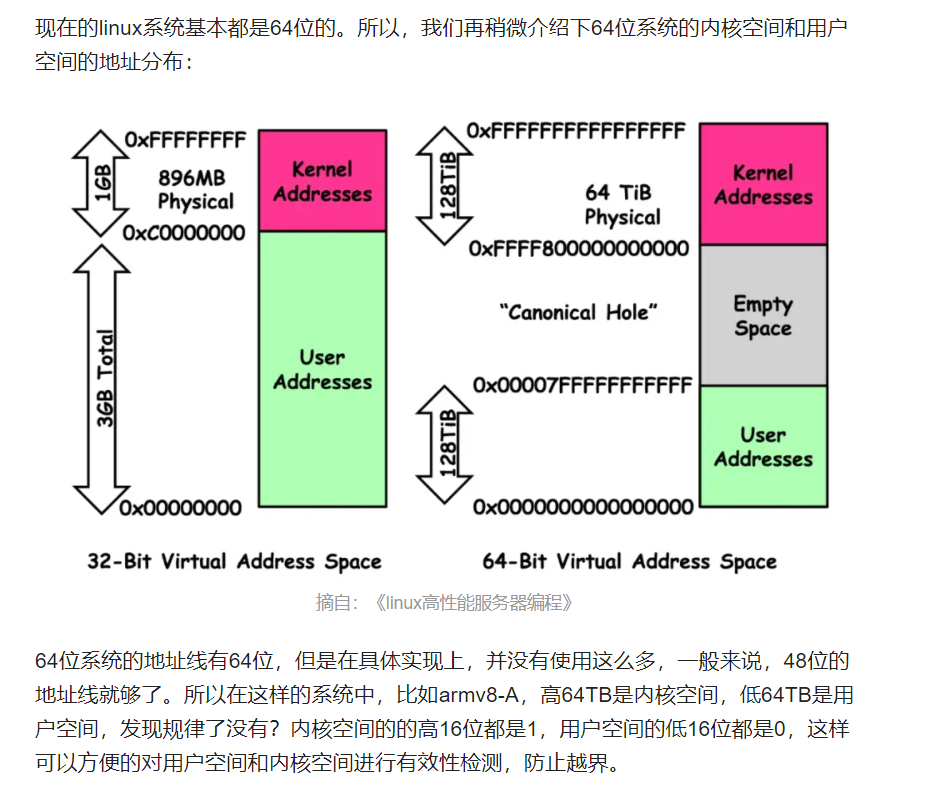
内核空间与用户空间的地址界限不是固定的,内核里有个配置叫config_page_offset来设置界限

x86段页式内存管理和页表映射机制
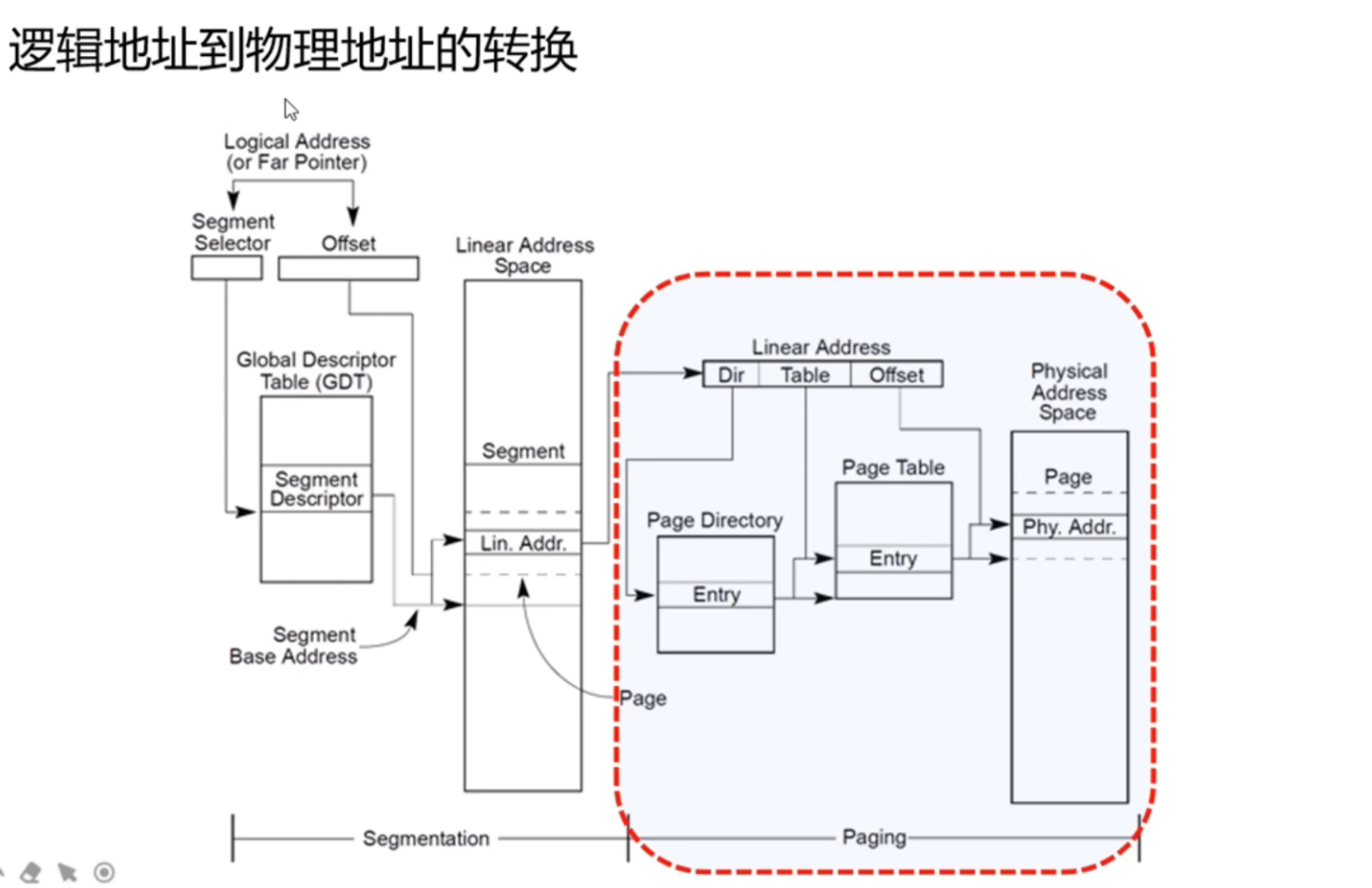
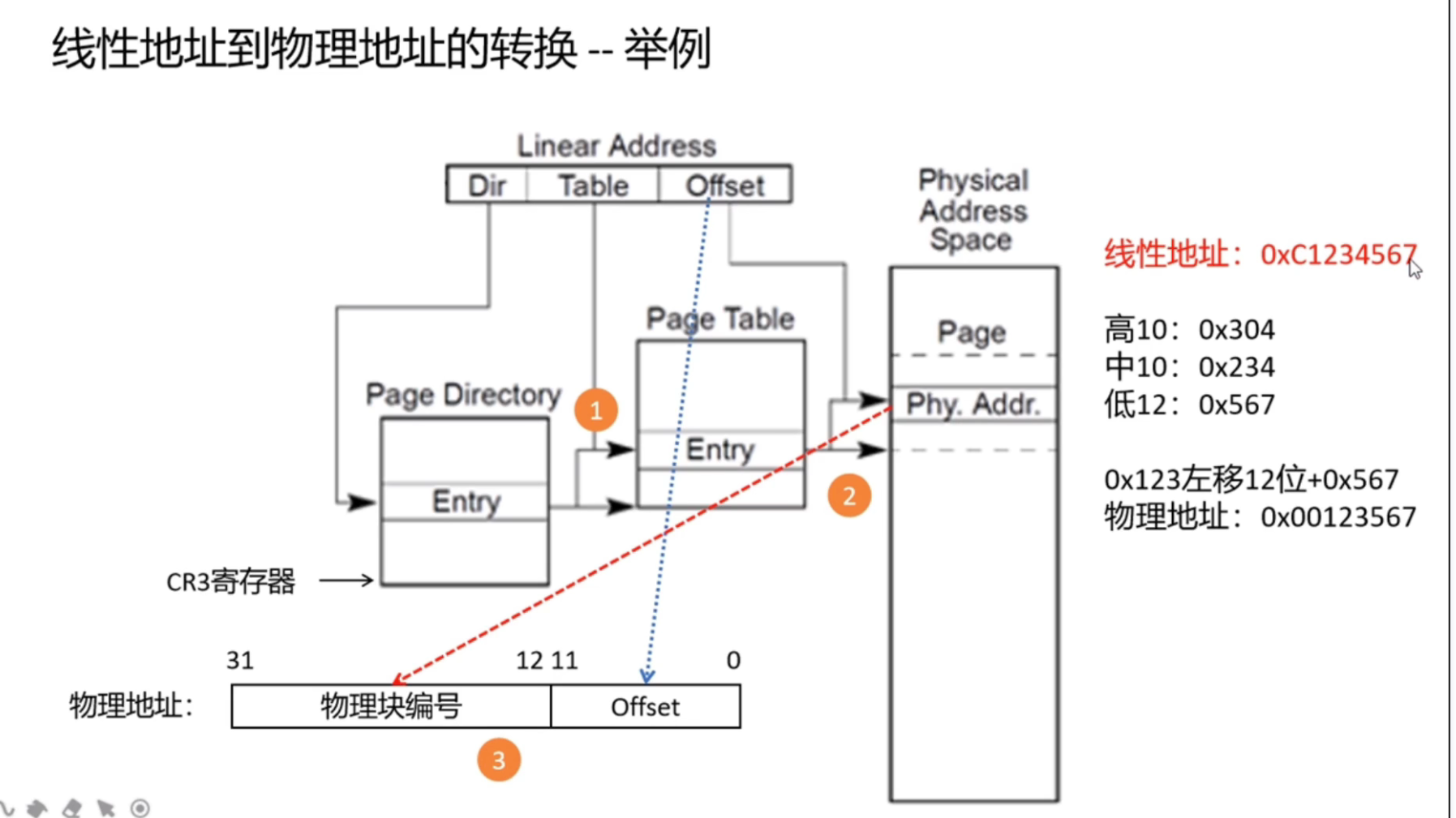
一个页目录有1024个节点,一个节点4字节,总共4K,正好一个页,然后页表也是一样,也就是页目录1024×页表1024×物理页4KB,正好就是32位系统的最大内存限制4GB
CR3寄存器存放了页目录表的物理内存基址,每当进程切换时,Linux就会把下一个将要运行进程的页目录表物理内存基地址等信息存放到CR3寄存器中。按我自己的理解,每个进程都保存了页目录表项(索引),加上CR3的基址,就找到了对应的页目录
linux内核同步机制之semaphore使用

先定义一个信号量struct semaphore sema;,在临界区前面加down(&sema);加锁,等出临界区时用up(&sema);解锁

semaphore的内核源码实现
测试程序
semaphore结构体

双向链表在include/linux里面的types.h定义了

初始化函数
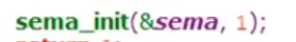

down函数

count在初始化的时候设置了,当第一个进程调用down的时候,检测sem->count是否大于0,如果是count就自减1,如果不是,也就是第二个进程调用的时候,锁被占用了,就进入__down函数

TASK_INTERRUPTIBLE: 处于等待队伍中,等待资源有效时唤醒(比如等待键盘输入、socket连接、信号等等),但可以被中断唤醒.一般情况下,进程列表中的绝大多数进程都处于 TASK_INTERRUPTIBLE状态.毕竟皇帝只有一个(单个CPU时),后宫佳丽几千;如果不是绝大多数进程都在睡眠,CPU又怎么响应得过来. TASK_UNINTERRUPTIBLE:处于等待队伍中,等待资源有效时唤醒(比如等待键盘输入、socket连接、信号等等),但不可以被中断唤醒.
MAX_SCHEDULE_TIMEOUT设置等待时间,一般为很大很大的数
__down_common函数
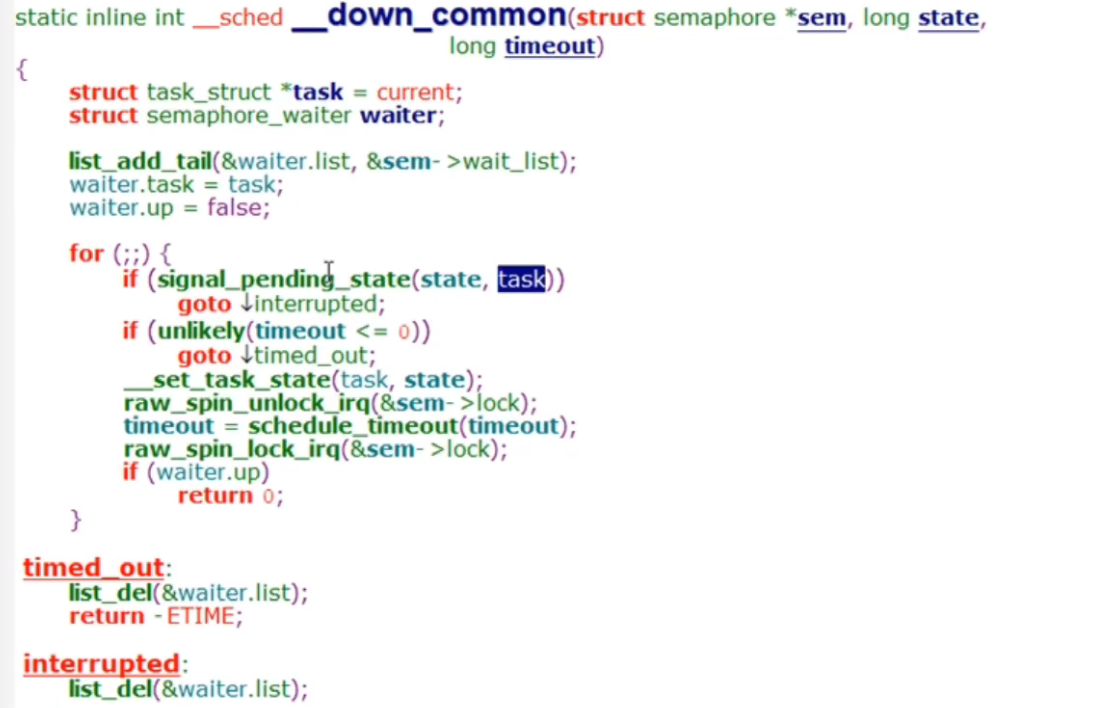

首先将当前进程赋值给task,然后下面三句话总的意思将当前进程加入到等待队列

然后进入for循环,判断是否有信号打断当前进程,因为state是TASK_UNINTERRUPTIBLE,所以直接就return 0了,前面两个if都可以不用看

__set_task_state函数将当前进程的状态设置为TASK_UNINTERRUPTIBLE,让其进入睡眠不可中断状态,释放出资源给别的进程

然后是raw_spin_unlock_irq,这里释放了一个锁,实际上是释放的下图中的锁,原因1是因为自旋锁的开销是非常大的,所以应该让尽可能少的代码放到被自旋锁保护的临界区,
原因2:schedule_timeout(timeout)该方法会让需要延迟的任务睡眠到指定的延迟时间耗尽后再重新运行。但该方法也不能保证睡眠时间正好等于指定的延迟时间,只能尽量使睡眠时间接近指定的延迟时间。当指定的时间到期后,内核唤醒被延迟的任务并将其重新放回运行队列。唯一的参数是延迟的相对时间,单位为jiffies,上列中将相应的任务推入可中断睡眠队列,睡眠s秒。因为任务处于可中断状态,所以如果任务收到信号将被唤醒。如果睡眠任务不想接受信号,可以将任务状态设置为TASK_UNINTERRUPTIBLE,然后睡眠。注意,在调用schedule_timeout()函数前必须首先将任务设置成上面两种状态之一,否则任务不会睡眠。
注意,由于schedule_timeout()函数需要调度程序,所以调用它的代码必须保证能够睡眠。简而言之,调用代码必须处于进程上下文中,并且不能持有锁。在这个过程中发生睡眠,而自旋锁是不允许睡眠的
所以呢,schedule_timeout(timeout)这句代码直到当前进程重新被调度了才会返回,然后继续往下执行代码,又加了一把锁,检查waiter.up是否为true,如果不是就一直循环
那什么时候waiter.up等于true呢,还记得前面加信号量锁的步骤吗,先down(&sema)加锁,up(&sema)解锁,就是这个up函数将waiter.up等于true的

up函数

首先看wait_list里边是否为空,如果是就count++,如果不是就调用__up函数
__up函数

首先将wait_list将等待的进程拿出来,从waiter->list里边删掉,然后将up设为true,唤醒该进程,这样之前的for循环就结束掉了,锁就解开了
内核原子变量的说明和使用
由于信号量涉及到进程的调度导致开销很大,如果仅涉及int变量修改同步,可以使用原子变量,使其变成一个原子操作,这样就不会被其他进程打断

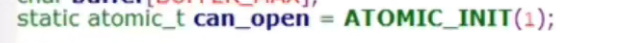


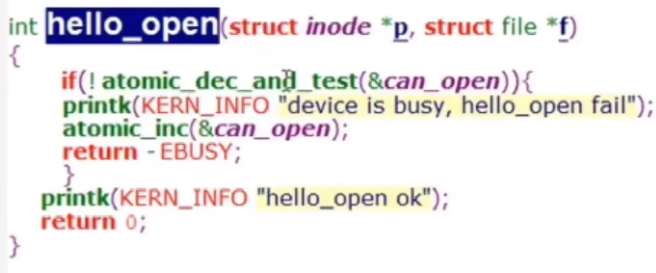
atomic_dec_and_test(&can_open)会将can_open减一,然后检查是否等于0,如果等于0就返回true
atomic_inc(&can_open)会加一,让其变回原样
atomic的内核源码实现
1 | |
1 | |
1 | |
spinlock的说明和使用方法


初始化spin lock

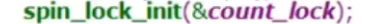
使用


spinlock内核源码(UP版)



__ ARMEB__ 表示大端序

初始化函数
略过check

先不管debug的spinlock




就一个目的,把owner和next设置为0
spin_lock()函数



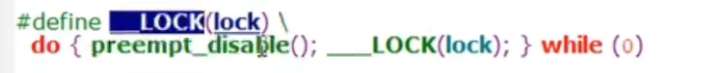
主要是将抢占关闭
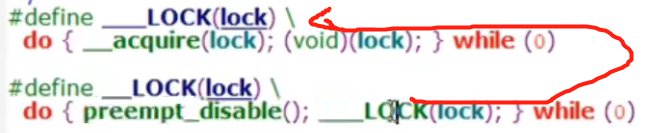
spinlock在SMP下的源码实现


关闭抢占,同步核心信息

实际上就是第三个参数调用第一个参数,do_raw_spin_lock(lock)


1 | |
unlock就是onwer++

spinlock、rw spinlock、seqlock、rcu机制比较


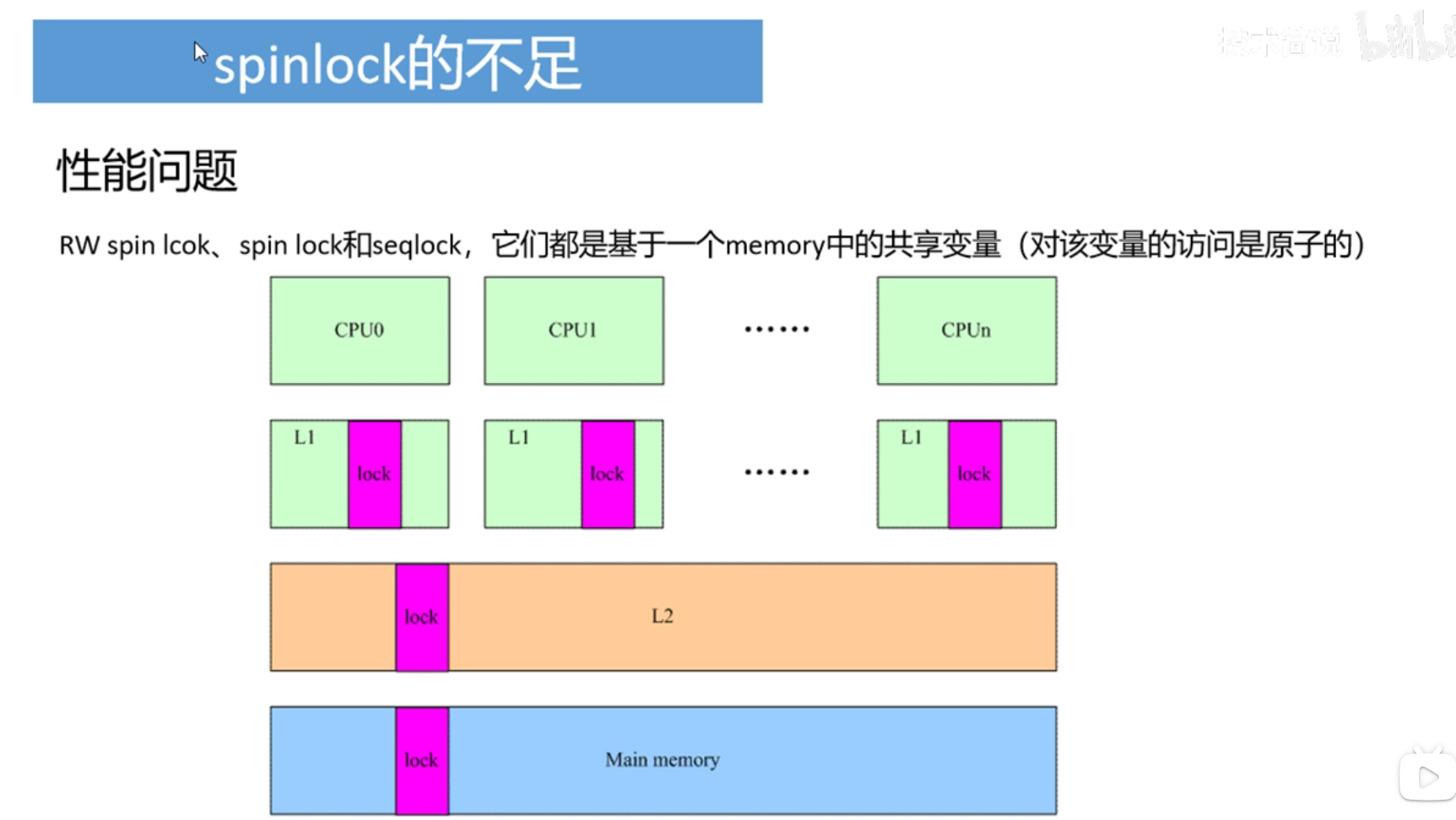
当多个cpu进入临界区前,会涉及到共享内存lock的访问,当CPU0得到了lock,就会操作lock改变lock的值,当lock的值发生变化时,其它CPU的L1缓存中的lock值就会失效,我们都知道,cpu会不断的访问内存获取lock的值,那么当L1失效了,它们就得去访问L2,如果L2也失效,就会去主存找,这样就会造成性能的开销,主要还是CPU和内存之间性能的发展不平衡造成的。

页框和伙伴算法以及slab机制
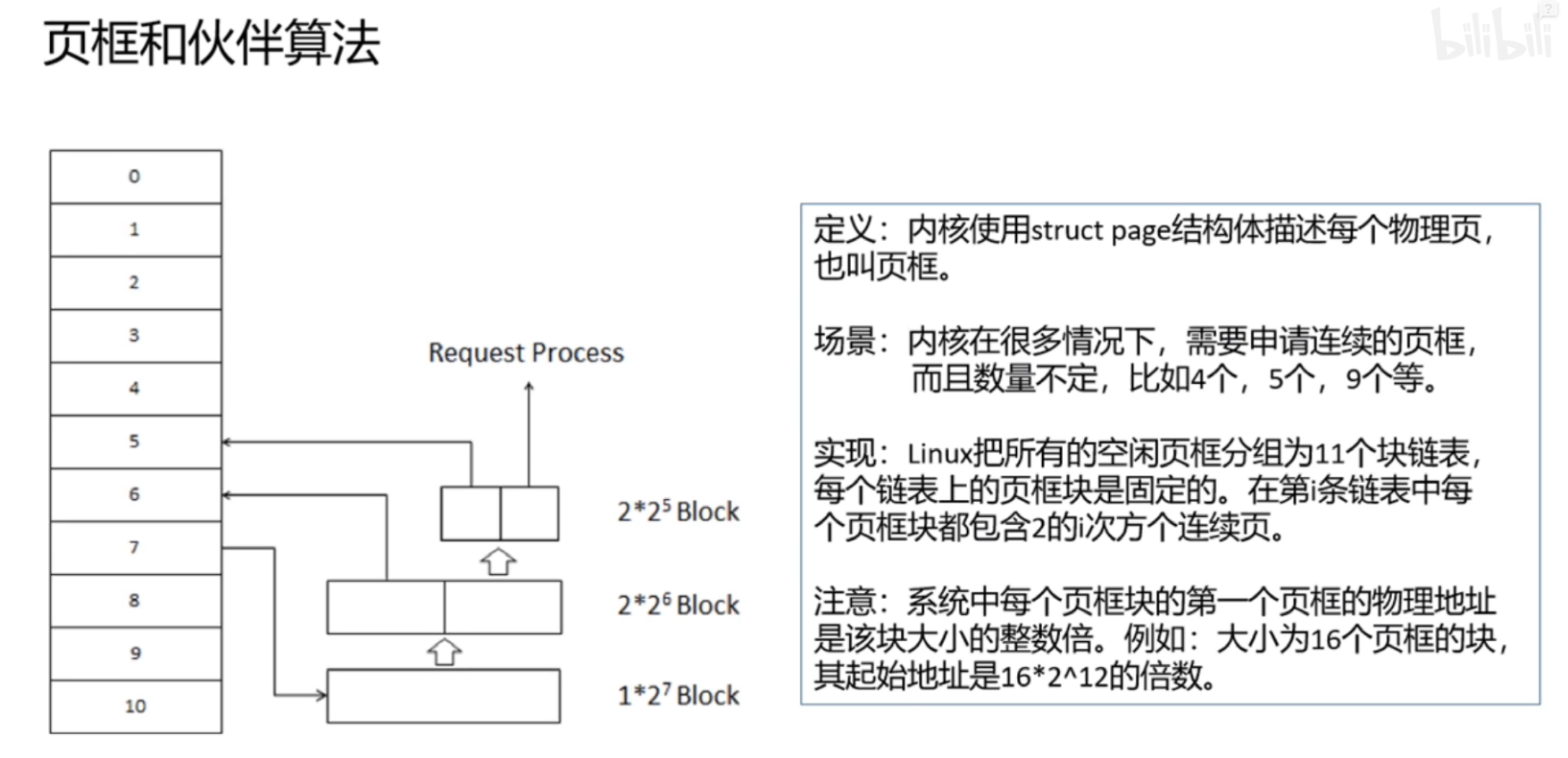
一个4K的页对应一个struct page结构体,所以有多少个页就有多少个struct page结构体


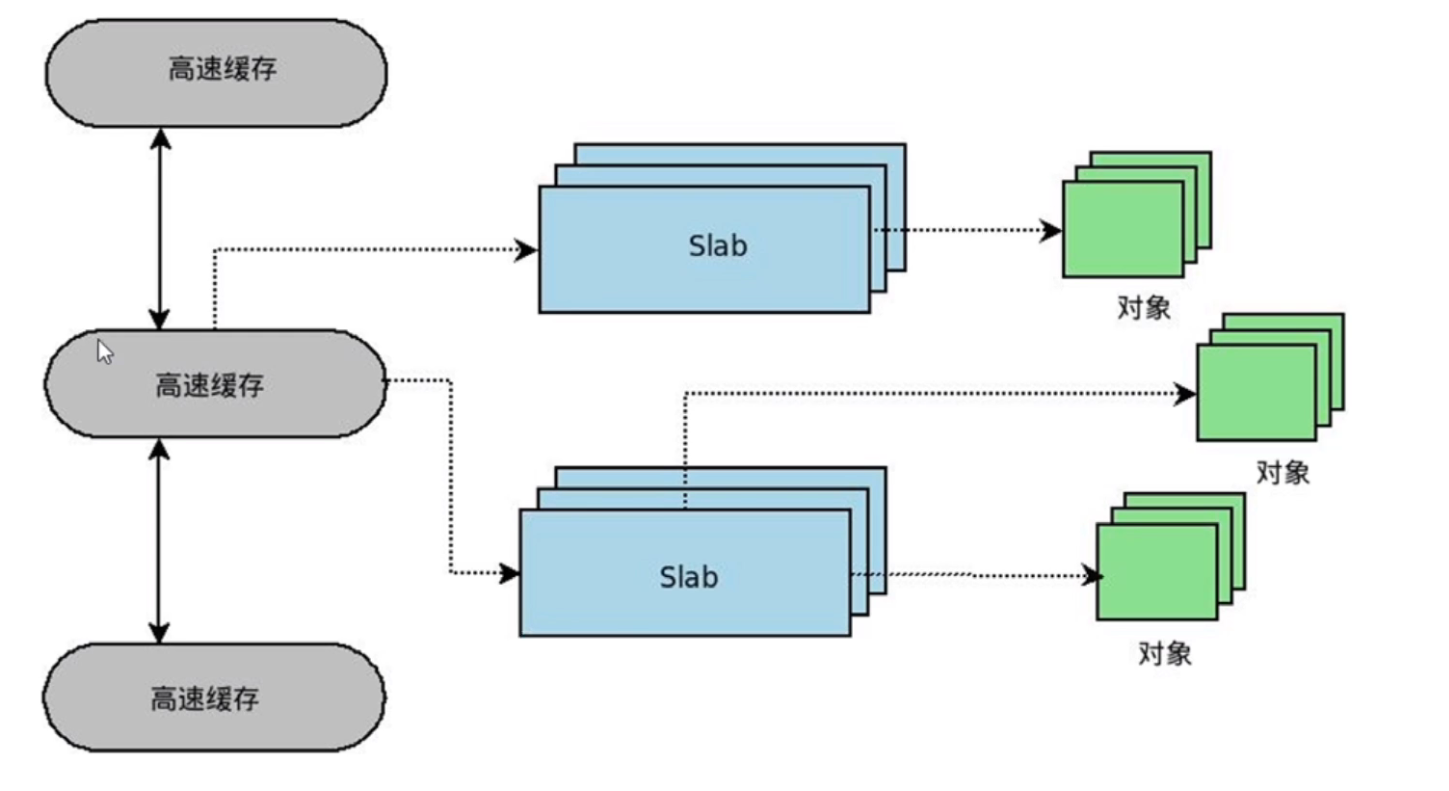
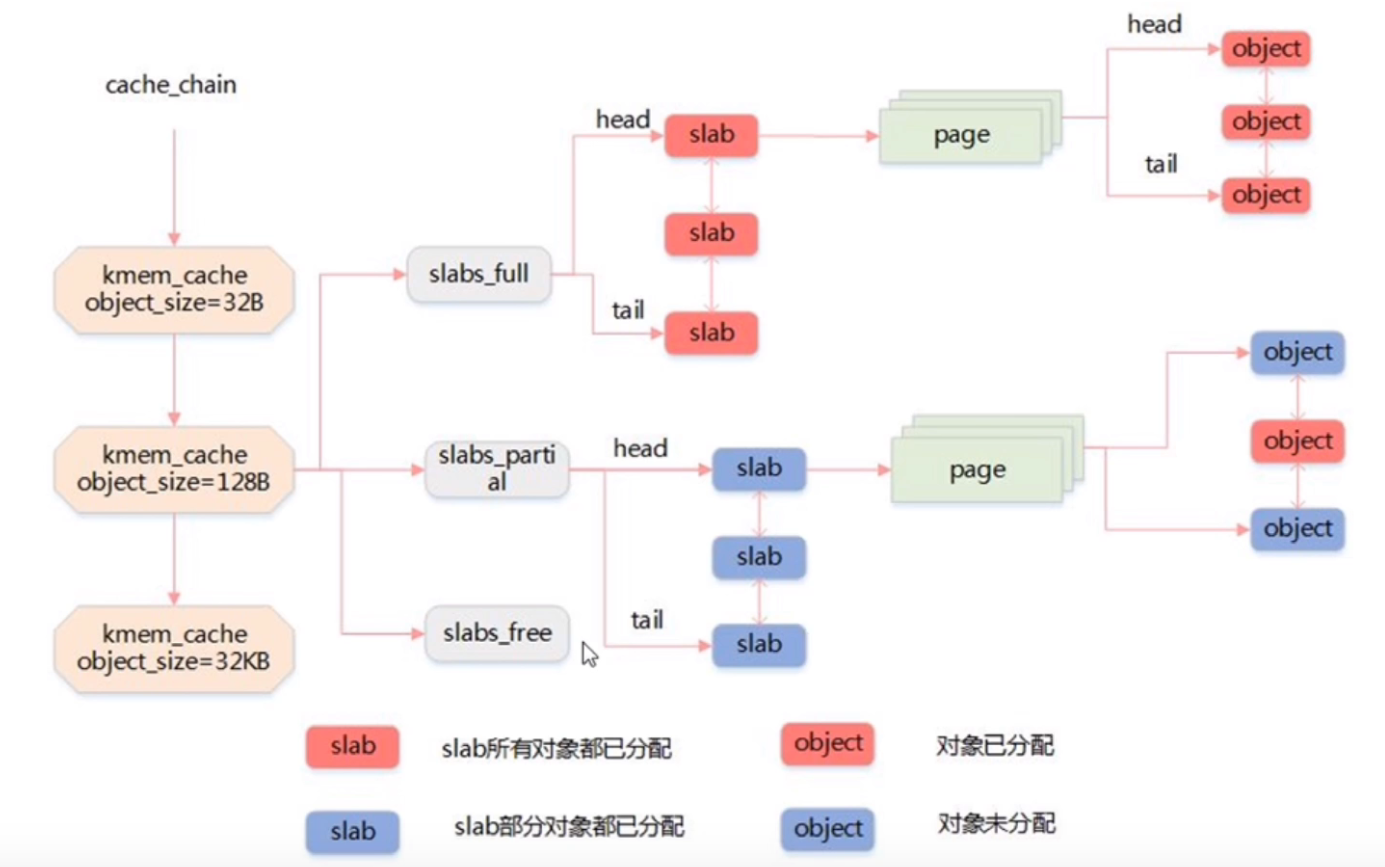

linux内核内存管理和分配方法概述
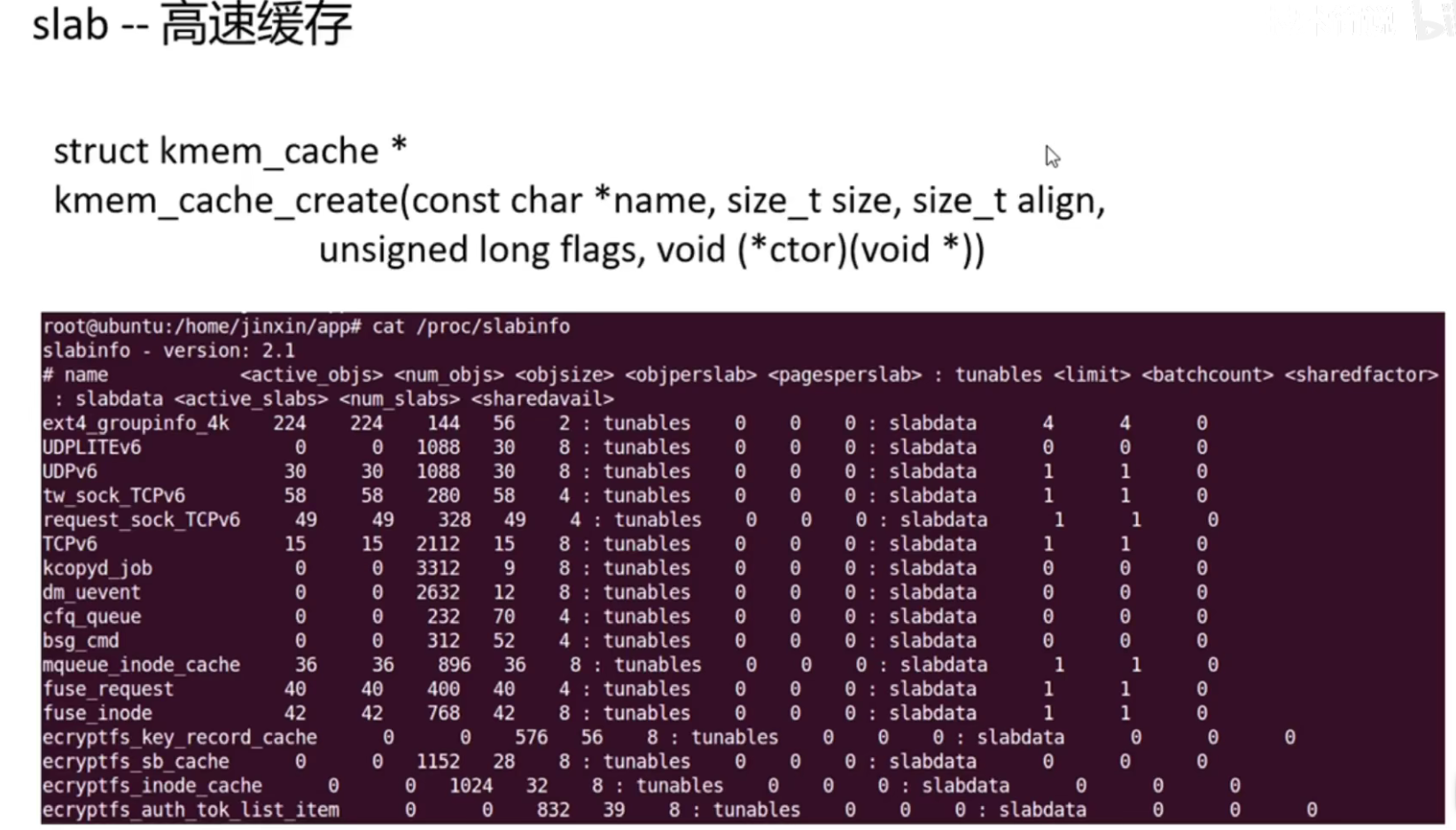


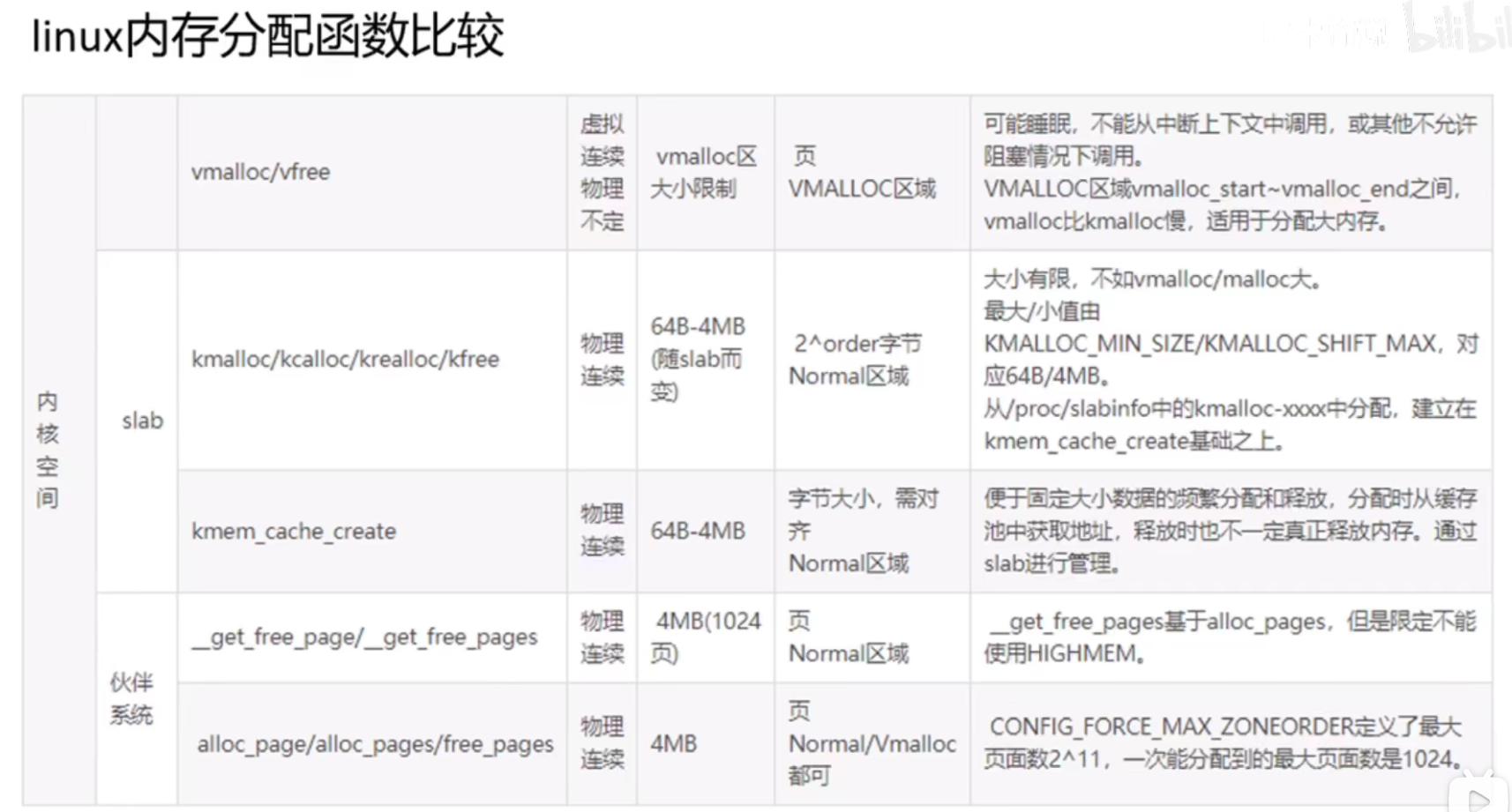
https://www.cnblogs.com/wangzahngjun/p/4977425.html
kmalloc()的内核源码实现
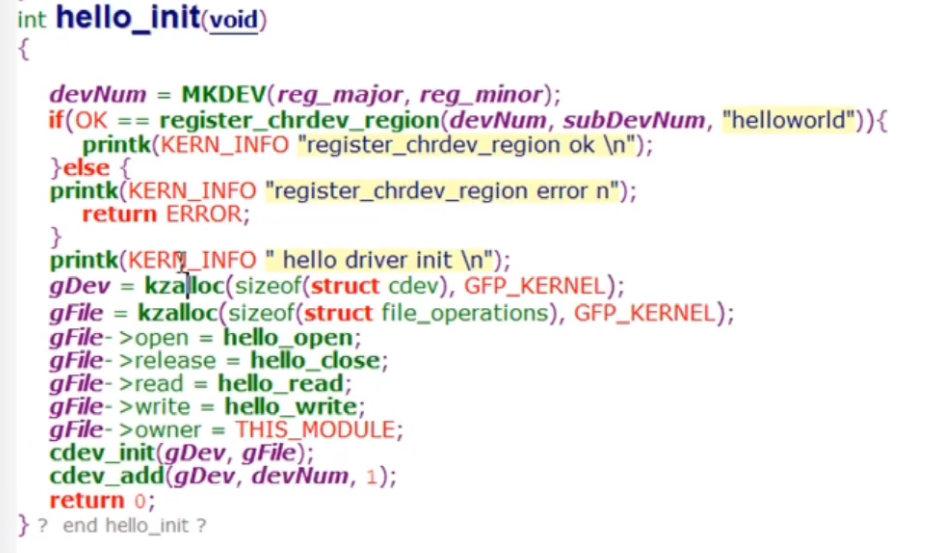
首先从kzalloc看起
1 | |

kzalloc调用了kmalloc将内存都设置为0
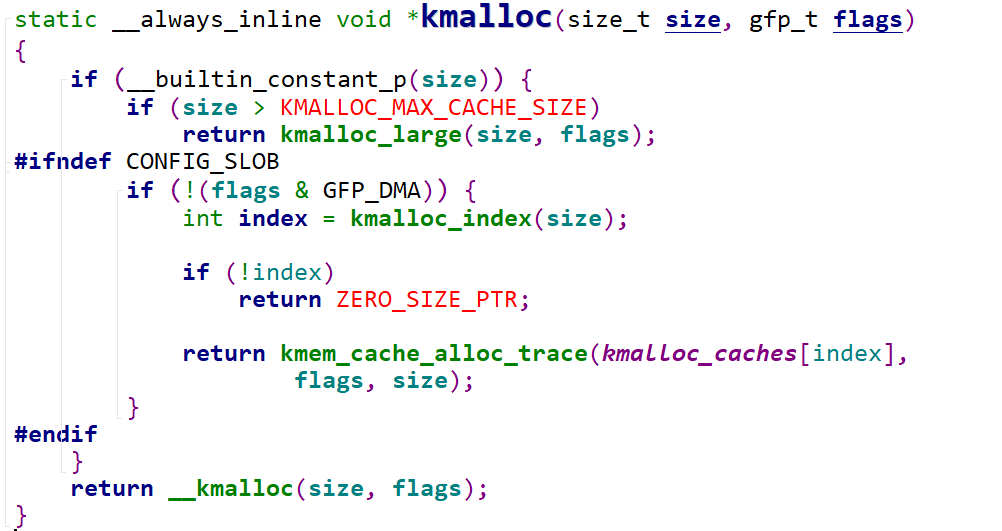
__builtin_constant_p()判断括号里的值是否为预定义的常量,但是一般size都是我们自己定义的,所以先省略不看,直接看__kamlloc,在slab.c里

然后是__do_kmalloc
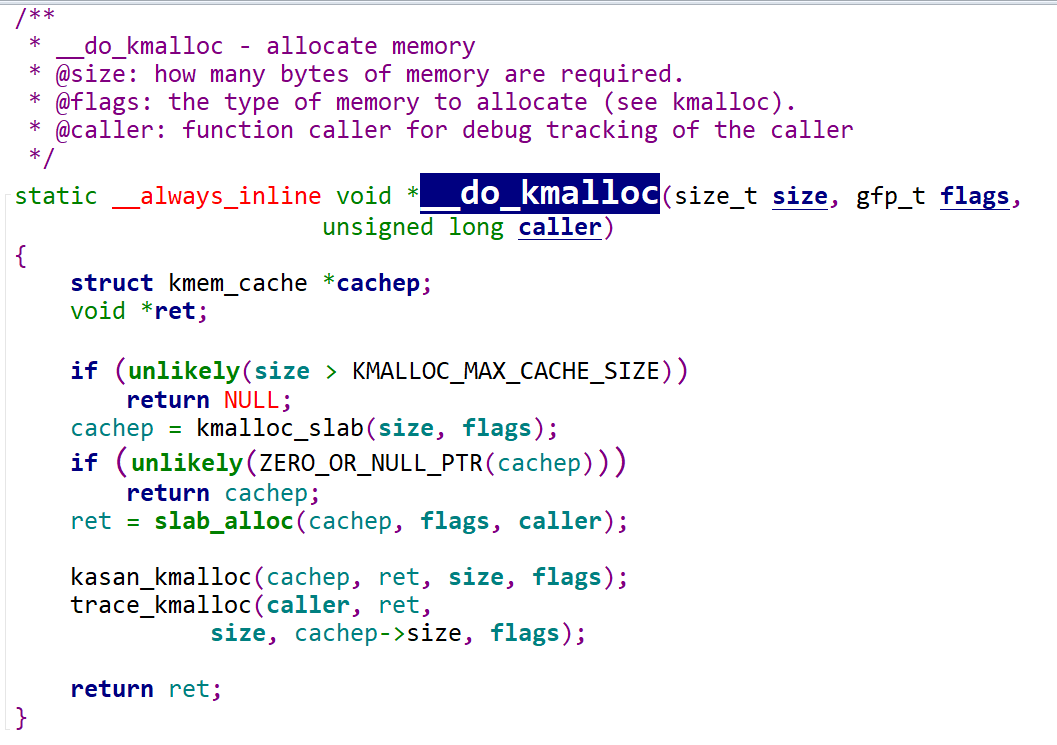
1 | |
kmalloc_slab
在slab_common.c里
1 | |
1 | |
1 | |
__clz会返回32位数最高位有多少个0,fls()就会32减去__clz返回0的个数

这个时候就要去了解kmalloc_caches[index]这个数组是什么了
1 | |
看一下如何初始化kmalloc_caches[]
1 | |
1 | |
初始化一个高速缓存,名字是name,大小是size

然后看一下new_kmalloc_cache(int idx, unsigned long flags)参数idx和高速缓存的关系
1 | |
slab_alloc
1 | |

1 | |
然后是cache_alloc_refill,它实现如果没有对象可以用来分配时,就使用它来新增新的对象。
1 | |
1 | |
1 | |
1 | |
1 | |
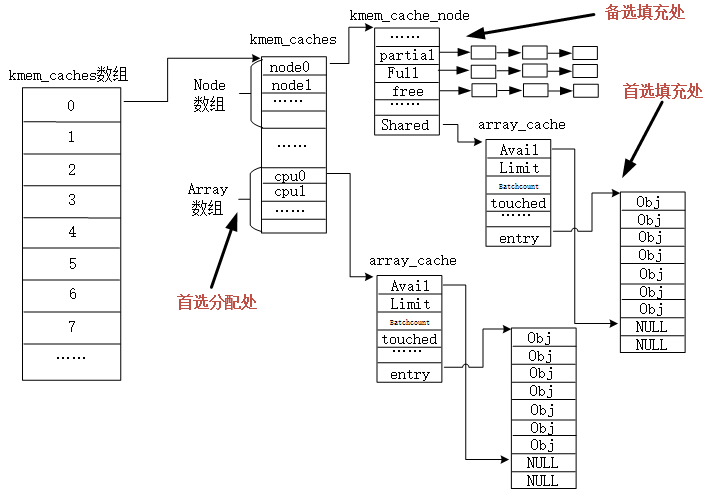
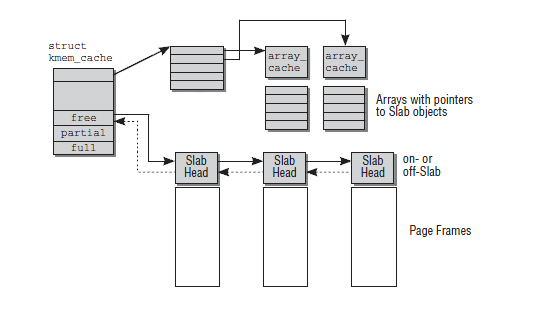
- 每个CPU都有它们自己的硬件高速缓存,当此CPU上释放对象时,可能这个对象很可能还在这个CPU的硬件高速缓存中,所以内核为每个CPU维护一个这样的链表,当需要新的对象时,会优先尝试从当前CPU的本地CPU空闲对象链表获取相应大小的对象。
- 减少锁的竞争,试想一下,假设多个CPU同时申请一个大小的slab,这时候如果没有本地CPU空闲对象链表,就会导致分配流程是互斥的,需要上锁,就导致分配效率低。
这个本地CPU空闲对象链表在系统初始化完成后是一个空的链表,只有释放对象时才会将对象加入这个链表。当然,链表对象个数也是有所限制,其最大值就是limit,链表数超过这个值时,会将batchcount个数的对象返回到所有CPU共享的空闲对象链表(也是这样一个结构)中。
所有CPU共享的空闲对象链表
原理和本地CPU空闲对象链表一样,唯一的区别就是所有CPU都可以从这个链表中获取对象,一个常规的对象申请流程是这样的:系统首先会从本地CPU空闲对象链表中尝试获取一个对象用于分配;如果失败,则尝试来到所有CPU共享的空闲对象链表链表中尝试获取;如果还是失败,就会从SLAB中分配一个;这时如果还失败,kmem_cache会尝试从页框分配器中获取一组连续的页框建立一个新的SLAB,然后从新的SLAB中获取一个对象。对象释放过程也类似,首先会先将对象释放到本地CPU空闲对象链表中,如果本地CPU空闲对象链表中对象过多,kmem_cache会将本地CPU空闲对象链表中的batchcount个对象移动到所有CPU共享的空闲对象链表链表中,如果所有CPU共享的空闲对象链表链表的对象也太多了,kmem_cache也会把所有CPU共享的空闲对象链表链表中batchcount个数的对象移回它们自己所属的SLAB中,这时如果SLAB中空闲对象太多,kmem_cache会整理出一些空闲的SLAB,将这些SLAB所占用的页框释放回页框分配器中。
这个所有CPU共享的空闲对象链表也不是肯定会有的,kmem_cache中有个shared字段如果为1,则这个kmem_cache有这个高速缓存,如果为0则没有。
一般一级缓存叫本地CPU缓存,别的核心访问不了,二级缓存就是共享的,核心之间可以共享数据,都可以访问
关于SLAB着色
看名字很难理解,其实又很好理解,我们知道内存需要处理时要先放入CPU硬件高速缓存中,而CPU硬件高速缓存与内存的映射方式有多种。在同一个kmem_cache中所有SLAB都是相同大小,都是相同连续长度的页框组成,这样的话在不同SLAB中相同对象号对于页框的首地址的偏移量也相同,这样有很可能导致不同SLAB中相同对象号的对象放入CPU硬件高速缓存时会处于同一行,当我们交替操作这两个对象时,CPU的cache就会交替换入换出,效率就非常差。SLAB着色就是在同一个kmem_cache中对不同的SLAB添加一个偏移量,就让相同对象号的对象不会对齐,也就不会放入硬件高速缓存的同一行中,提高了效率。
进程虚拟地址空间管理机制


mm_users表示正在引用该地址空间的thread数目。是一个线程级的计数器。
mm_counter:表示这个地址空间被内核线程引用的次数+1
当 mm_user 和 mm_counter 都等于0的时候才会free这一块mm_struct,代表此时既没有用户级进程使用此地址空间,也没有内核级线程引用。



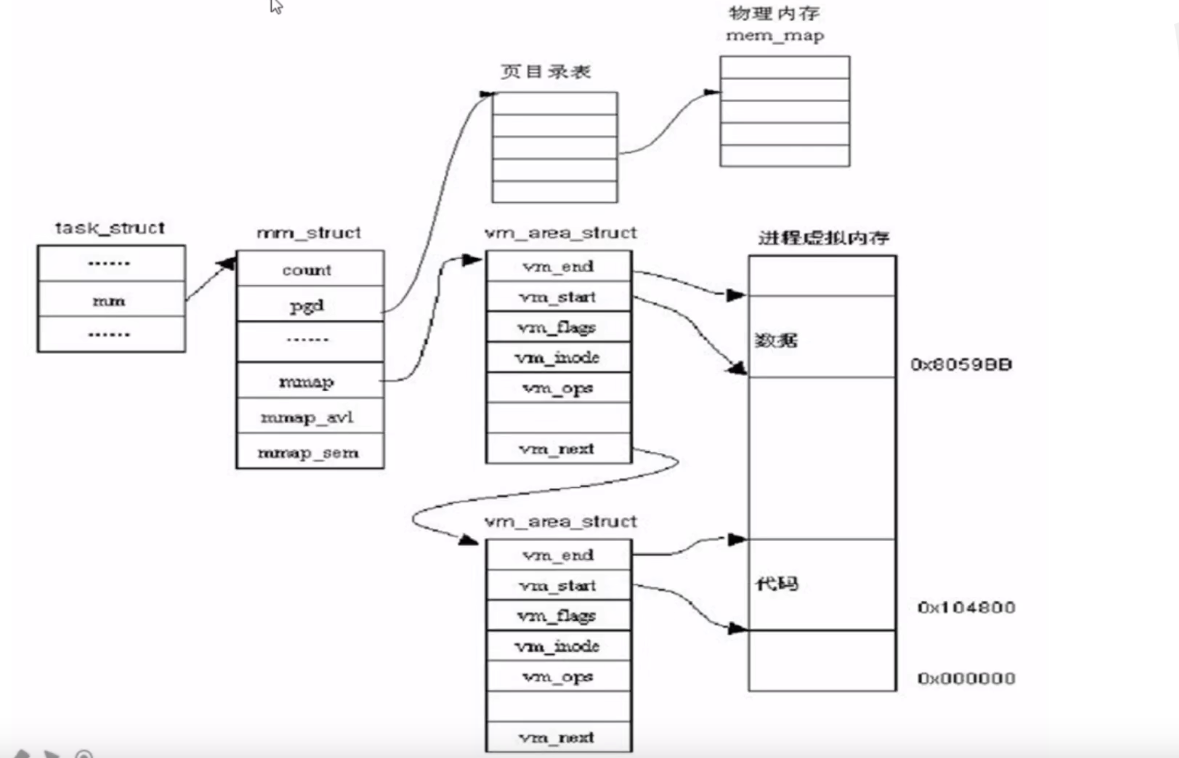


linux下同一个进程的不同线程之间如何共享虚拟地址空间?
1 | |
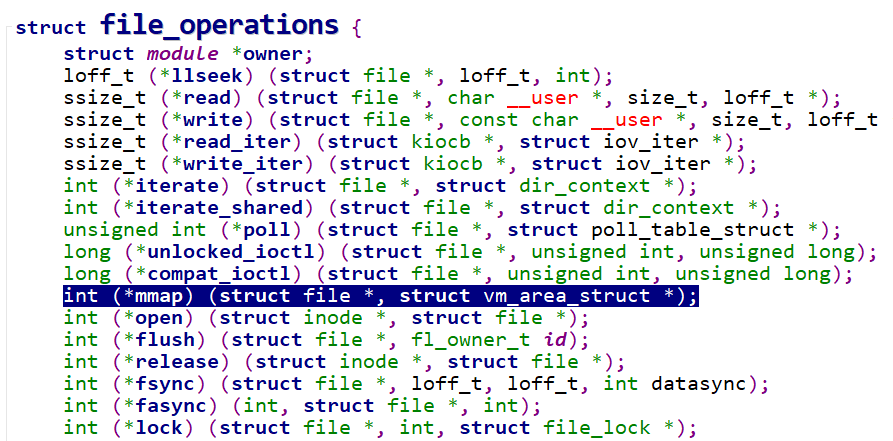
mmap()的内核实现



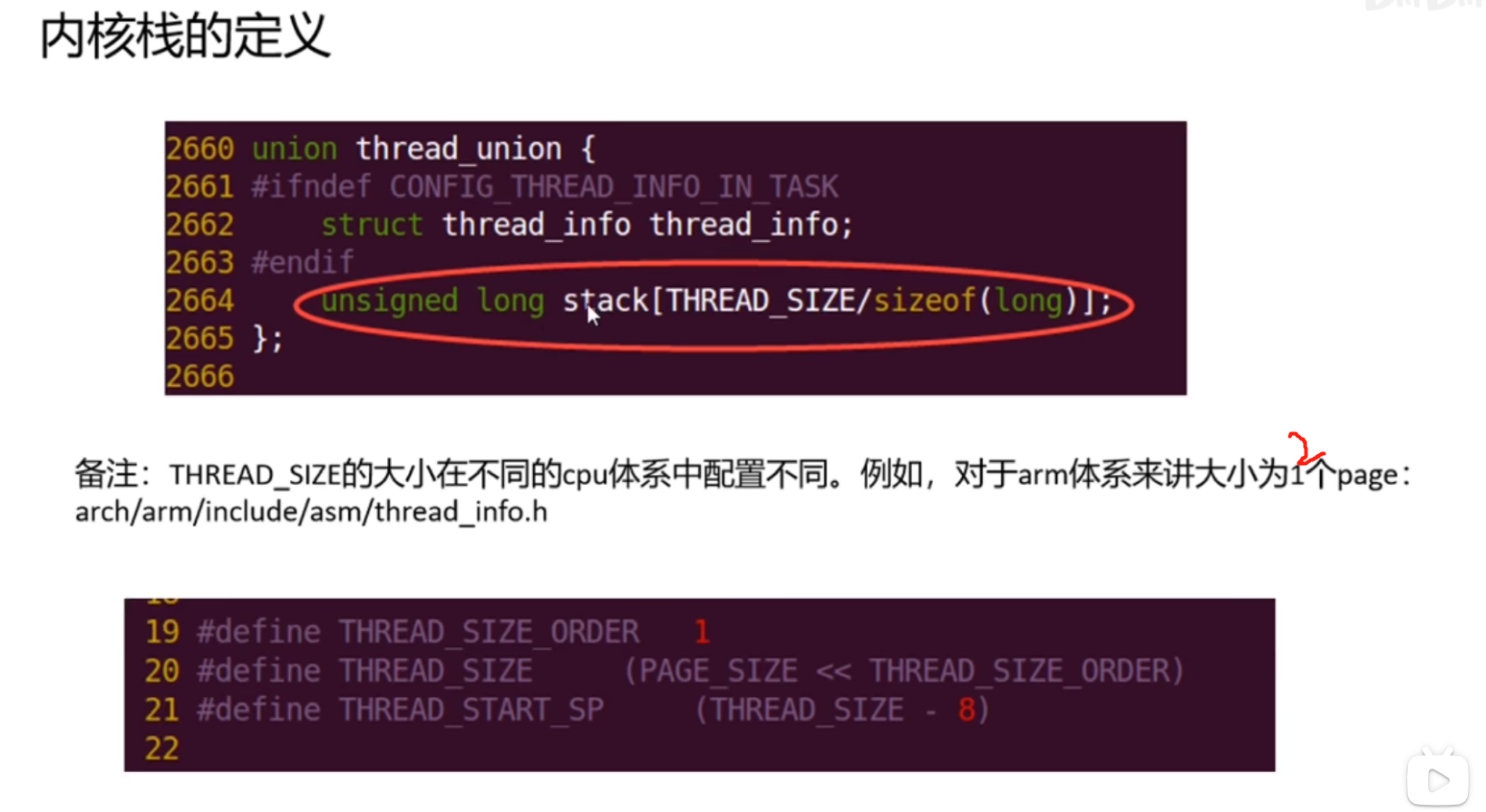
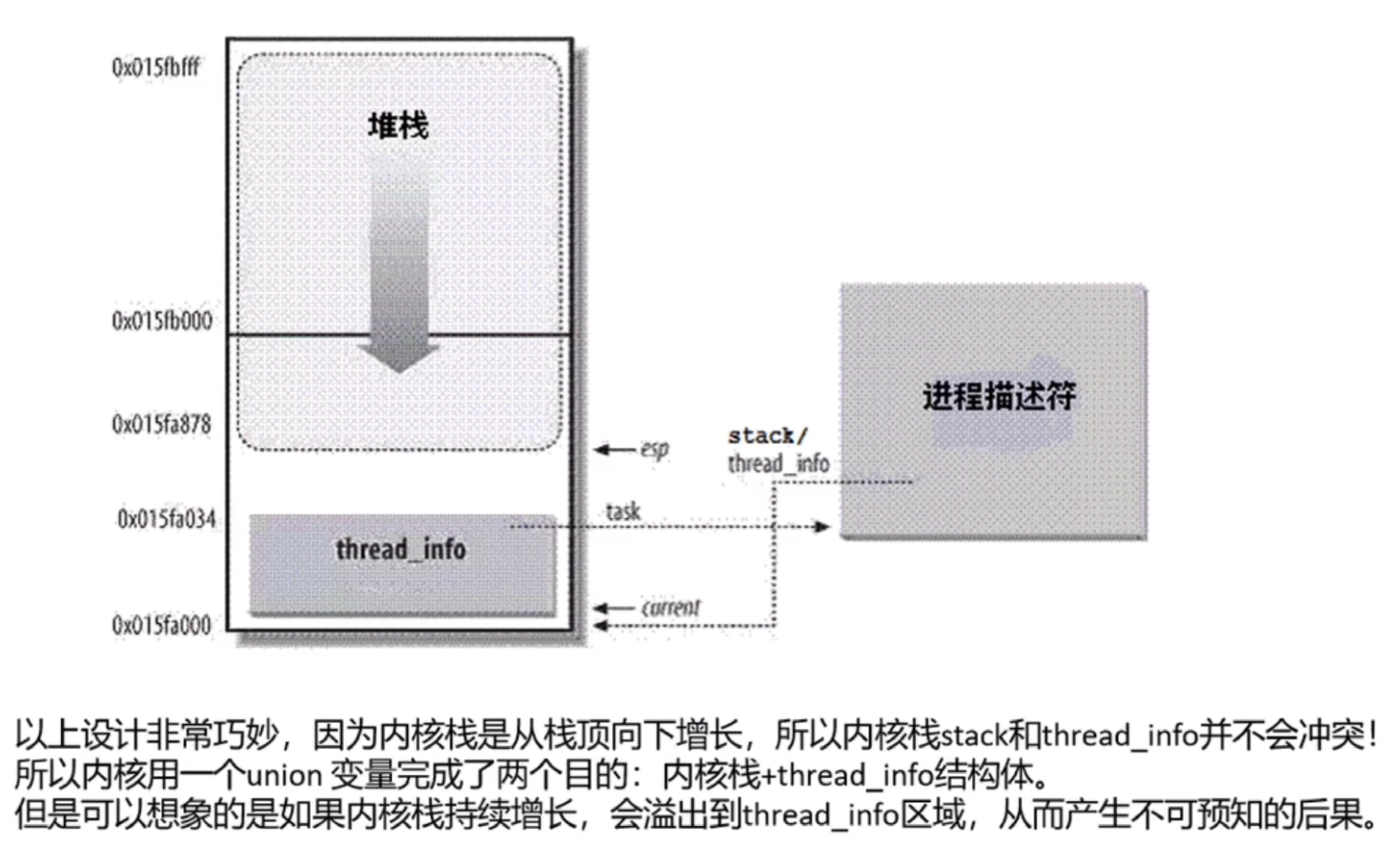
进程的用户栈和内核栈


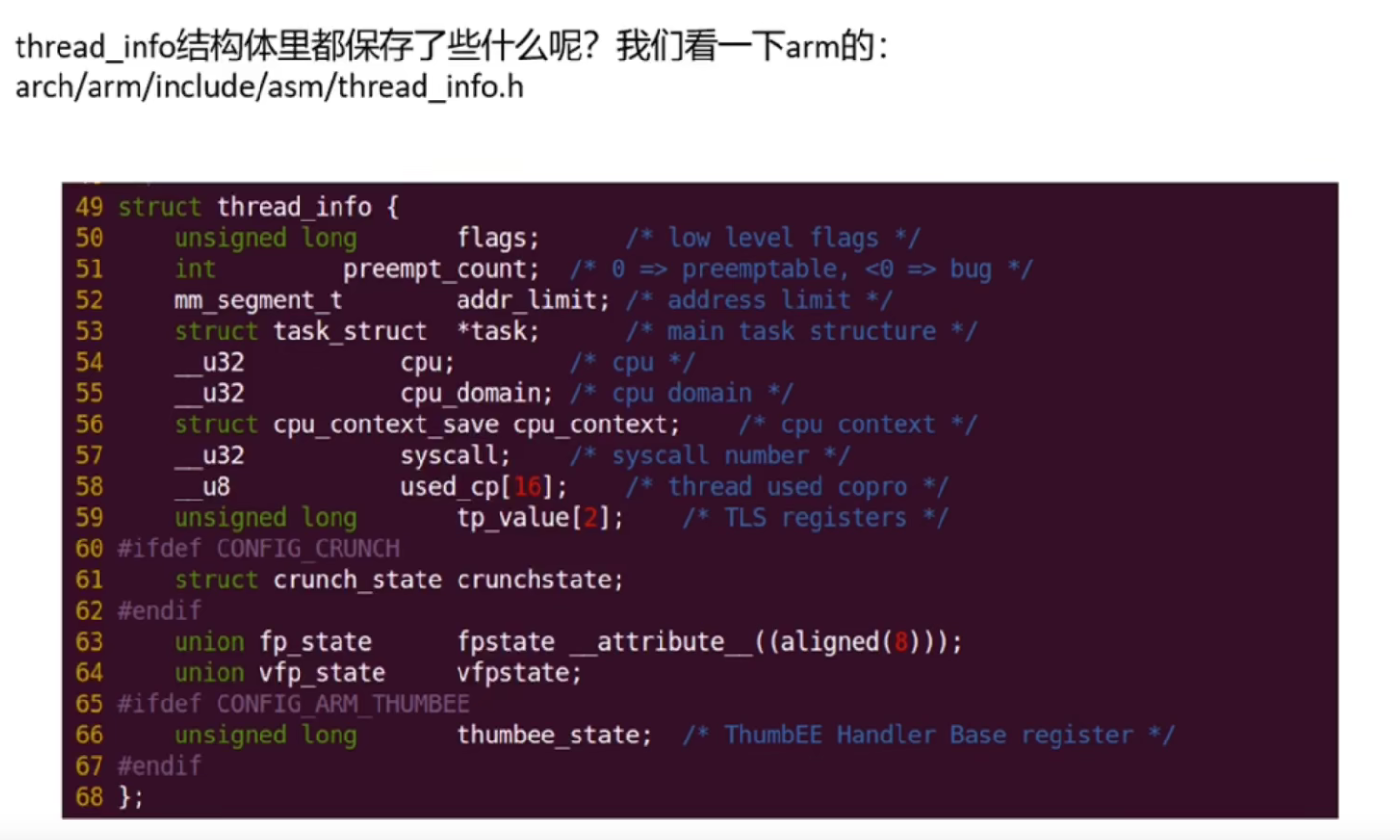
进程上下文和中断上下文
在thread_info里边
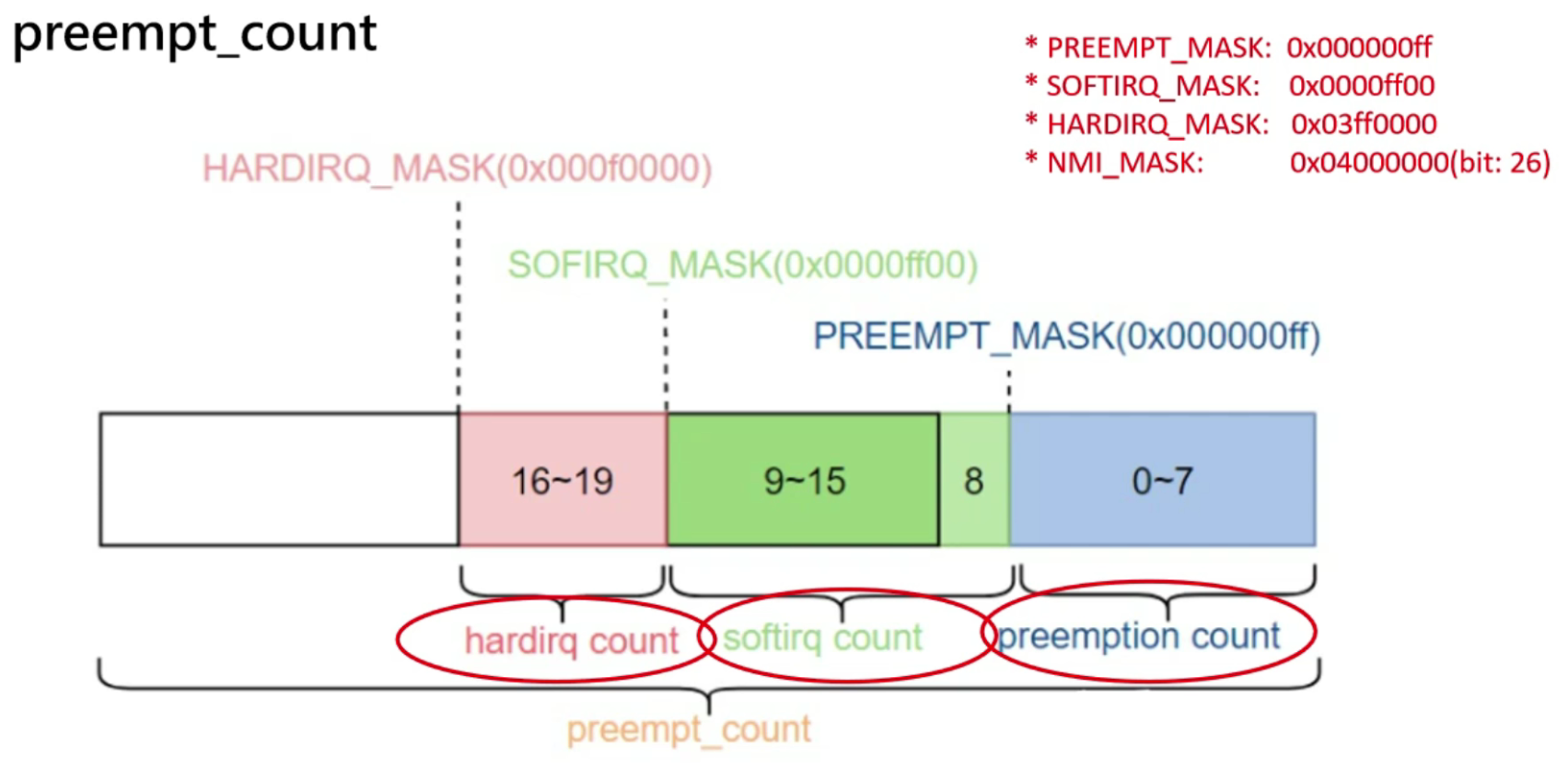
为了防止进程被softirq所抢占,关闭/禁止softirq的次数,比如每使用一次local_bh_disable(),softirq count高7个bits(bit 9到bit 15)的值就会加1,使用local_bh_enable()则会让softirq count高7个bits的的值减1。
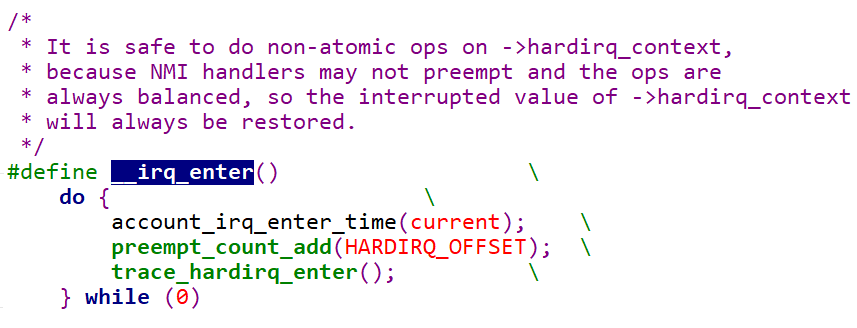
irq_enter()用于标记hardirq的进入,此时hardirq count的值会加1。irq_exit()用于标记hardirq的退出,hardirq count的值会相应的减1
在中断上下文中,调度是关闭的,不会发生进程的切换,这属于一种隐式的禁止调度,而在代码中,也可以使用preempt_disable()来显示地关闭调度,关闭次数由第0到7个bits组成的preemption count(注意不是preempt count)来记录。每使用一次preempt_disable(),preemption count的值就会加1,使用preempt_enable()则会让preemption count的值减1。preemption count占8个bits,因此一共可以表示最多256层调度关闭的嵌套。
如何获取preempt_count
1 | |
1 | |
获取中断上下文conut
1 | |
1 | |
中断上下文、进程上下文环境的进入时机
硬件中断上下文
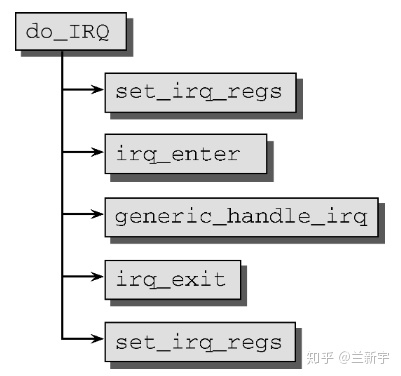
当外设产生一个中断以后,信号会传给CPU,然后CPU收到中断以后就会调用

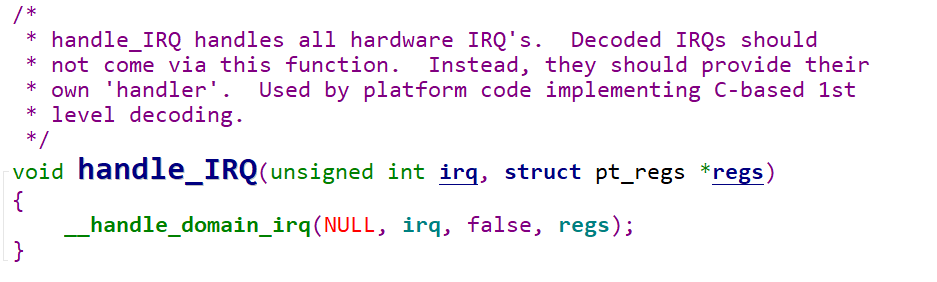
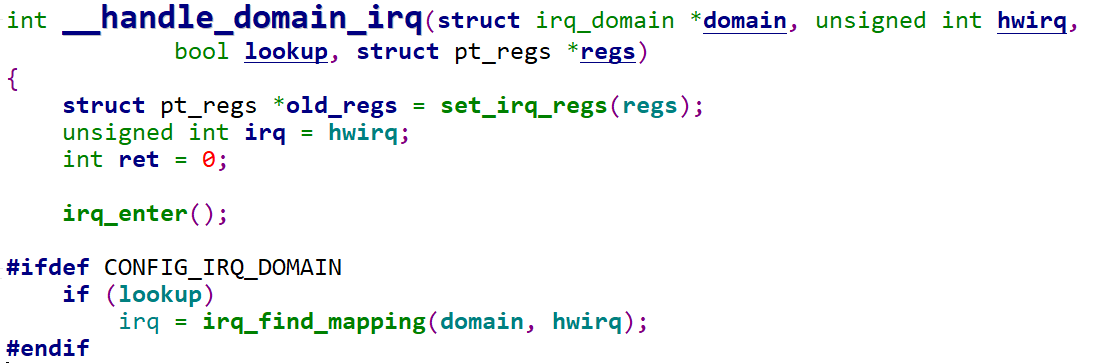

1 | |
此时调用in_irq()就会返回一个大于0的数,表示就处于硬件中断上下文中,那什么时候退出呢
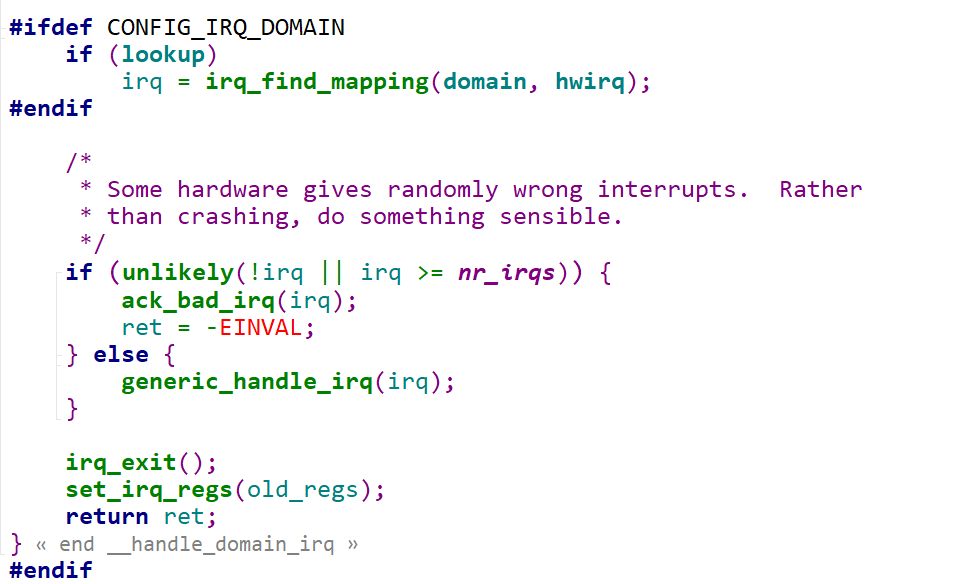
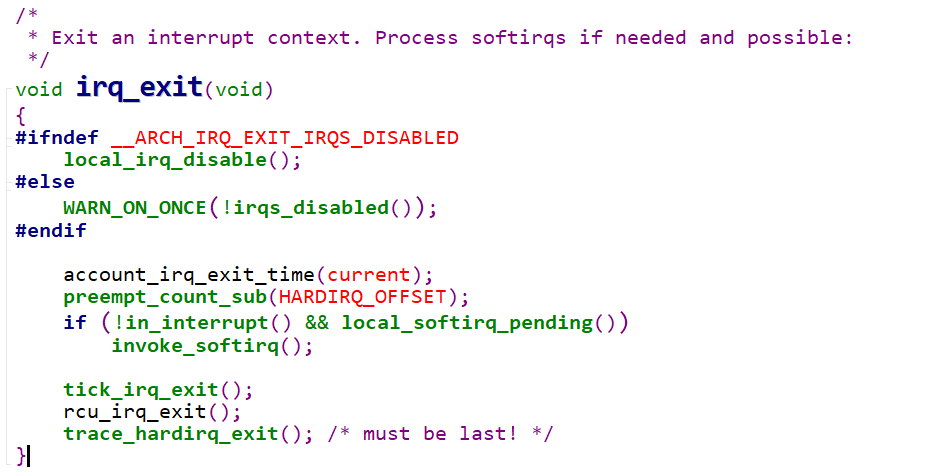
1 | |
中间的注册好的handler处于硬件中断上下文
软中断上下文
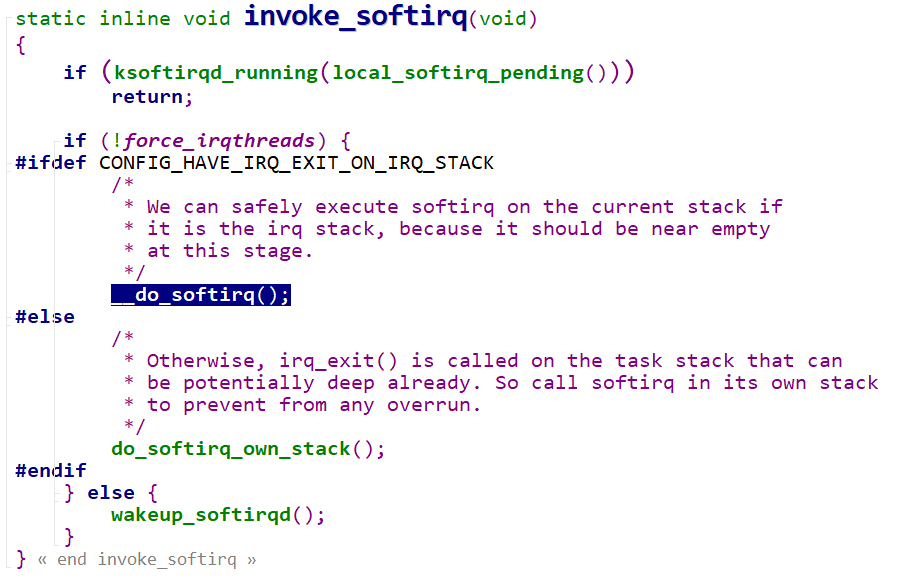
1 | |

软中断特点以及softirq注册和触发源码分析
https://zhuanlan.zhihu.com/p/80371745

中断的来源很多,所以softirq的种类也不少。内核的限制是不能超过32个,目前实际用到的有9个,其中两个用来实现tasklet(HI_SOFTIRQ和TASKLET_SOFTIRQ),两个用于网络的发送和接收操作(NET_TX_SOFTIRQ和NET_RX_SOFTIRQ),一个用于调度器(SCHED_SOFTIRQ),实现SMP系统上周期性的负载均衡。在启用高分辨率定时器时,还需要一个HRTIMER_SOFTIRQ。
为了有效地管理不同的softirq中断源,Linux采用的是一个名为softirq_vec[]的数组,数组的大小由NR_SOFTIRQS 表示,这是在编译时就确定了的,不能在系统运行过程中动态添加。为了便于多核的并行处理,它还被设计成了per-cpu类型的数组,也就是每个processor对应一个softirq_vec[]数组。每个数组元素代表一种softirq的种类,而数组里存放的内容则是其各自对应的执行函数。
1 | |

软中断的触发

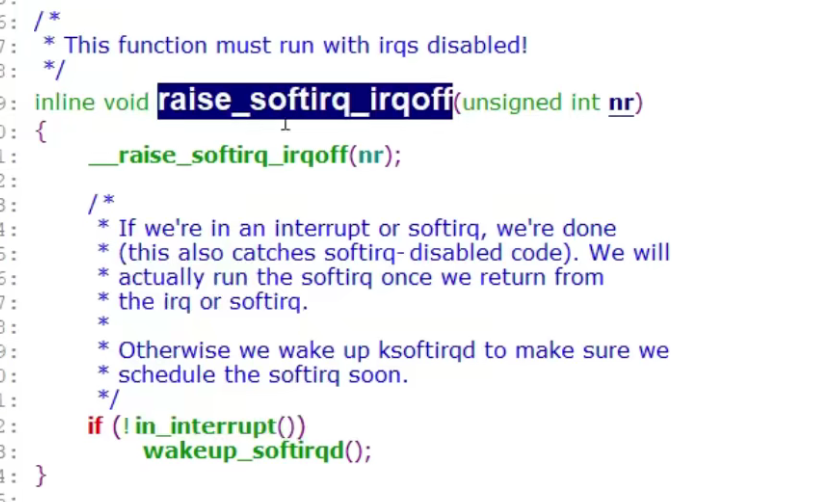


这里就是当前CPU的softiq_pending这个“中断寄存器”或上nr(软中断号?)



意思是哪个CPU触发了软中断号就由哪个CPU去执行软中断程序
软中断处理函数do_softirq()的执行时机
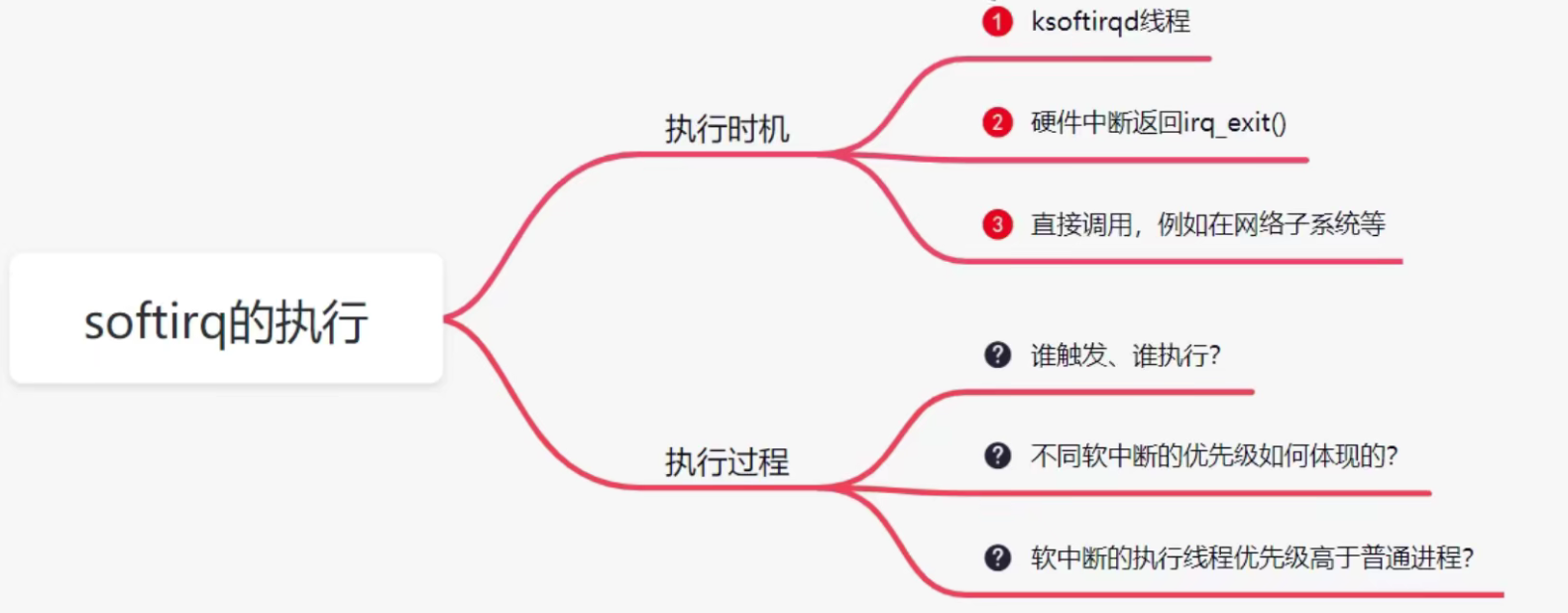
首先是ksoftirqd
1 | |
1 | |
##